言語情報処理
萩原研究室では 会話のできるロボット頭脳 を目指しています。人間が他の動物に比べて大きく優れている点として、言語の使用があげられます。例えば「山」は、わずか3本の縦線と、1本の横線からなっています。でも「山」から、多くの山や峰、その風景などをイメージすることができます。
つまり、文字とはとても高いレベルで抽象化されたものと考えることができます。そして私たちは、この文字を組み合わせて言語として使用し、さらに抽象レベルの高い情報処理を行なっています。このような処理を人工頭脳に行なわせるにはどうしたらよいでしょうか?
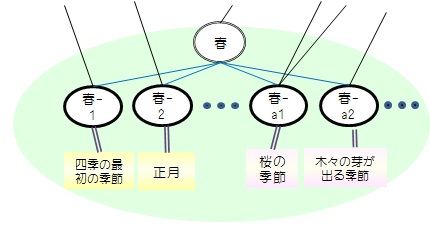
例えば「春」を広辞苑で調べると、四季の最初の季節、正月、勢いの盛んな時、青年期などと解説されています。しかし、暖かく眠気を誘う、桜の季節、入学式、木々や草花の芽が出る、新緑、など、私たちが「春」に対して持つイメージはあまり出てきません。
萩原研究室では、ディジタル化されたさまざまな言語資源(*)とニューラルネットワーク、Webなどを組み合わせたロボット頭脳の構築をめざしています。
(*)言語資源:さまざまな電子化辞書やコーパス(文例集)など
右図は萩原研にある言語資源の例で、他にも企業から提供いただいている膨大な会話データなどがあります。

1) ディジタル化された言語資源の統合
→ 多機能ニューラルネットワーク連想記憶へ
人間は、膨大量の記憶や何げない常識を持っています。これらは大脳皮質での長期記憶部に、記憶の分類では、宣言的知識の記憶の意味記憶に対応します。萩原研では、脳科学や認知科学の知見も用いながらこれらの記憶と効率的な連想や想起を可能とするニューラルネットワーク連想記憶構築をめざしています。
2) 思考や創造などを行うニューラルネットワークへ
人間の短期記憶や前頭葉での思考なども取り入れます。入力言語情報をニューラルネットワーク形式に展開し、長期記憶部へのアクセスを行なう事により、物事の概念やより深い意味の理解が可能となります。例えば、「リンゴ」に対しては、甘酸っぱい、果物、赤、青森でよくとれる、ジュースにもなる、などなどです。このように入力文章に答えが含まれていないような場合でも、長期記憶部へのアクセスを行なう事により正しい解答を出力したり、あるいはさらにレベルの高い推論あるいは創造などを可能とします。

3) 段階的な学習と、視覚情報処理、感性情報処理との融合
人間は幼稚園や小学校、中学、高校、そして大学等での教育を受けることにより、良質な知識を得て、さまざまなことを効率的に学びます。
現在のニューラルネットワークには、このような基礎的で発展的な教育や学習がありません。いきなり大量のデータを入力して強引にデータ内の因果関係を学ばせています。そこで萩原研では、
① 高品質で平易な知識やデータの学習
↓
② 次第に知識やデータのレベルや複雑度を上げて学習
↓
③ Webでの知識やデータの学習
という人間に近い学習をめざしています。Webは、電子化辞書などの言語資源とは異なり、ミスや誤りなども多く含まれています。そこではWebから得られる相異なる情報から、機械学習などより正しい情報を選択抽出する方法などの研究も必要になってきます。
さらに視覚情報処理、感性情報処理との融合も考慮してロボット頭脳の構築をめざします。
具体的な研究テーマには以下のものがあります。
研究内容
ニューラルネットワーク自動会話システム
言語により、私達は知識や感情のコミュニケーションを行います。また書物により、時間・空間的に離れた人とのコミュニケーションも可能となります。
会話は便利で使いやすく、究極のインタフェースとも考えらえます。社会でも、コールセンターをはじめその自動化の需要は非常に大きいものがあります。
萩原研究室ではこれまでに、ユーモア生成(漫才台本自動生成研究)、心に響く慰め文自動生成などの基礎研究を行ってきました。これらを組み合わせることにより、多様な個性や性格をもつ会話エージェントの構築をめざしています。

ニューラルネットワーク自動相談システム
将来の大きな目標としては、細心の気配りや気遣いのできる自動カウンセリングシステムをめざしています。その第一歩として、自動相談システムを開発しました。
これまでの自動会話システムは、大量の1対の会話データをもとにして学習を行っていたため、話の流れを考慮することが困難でした。そこで、VHRED (Latent Variable Hierarchical Recurrent Encoder-Decoder)というニューラルネットワークに、転移学習を導入することにより、会話の流れを考慮できる自動相談システムを提案しました。

ニューラルネットワーク常識判断システム
従来より人工知能の分野において、常識の扱いは極めて困難と言われていました。であれば、これは解決しなければなりません。
本研究は、分散表現学習ネットワークにより重要単語の推定を行い、その結果を用いる常識判断ニューラルネットワークの2段構成で、常識判断を行っています。

過去の研究
過去の研究はこちら